
Exercise 1: The finite-horizon decision problem#
Note
This page contains background information which may be useful in future exercises or projects. You can download this weeks exercise instructions from here:
You are encouraged to prepare the homework problems 1, 2 (indicated by a hand in the PDF file) at home and present your solution during the exercise session.
To get the newest version of the course material, please see Making sure your files are up to date
This weeks exercise will give you an introduction to the three main components of this course. They are:
- The Environment
Represented by an gymnasium
gymnasium.Envclass. This class contains the python-implementation of the problem we want to solve (Herlau [Her25], Subsection 4.3.1). It is responsible for maintaining an internal state (the state which the environment is in right now), and has a function which responds to actions (gymnasium.Env.step()).- The Agent
Represented as a
Agentclass. The agent interacts with the environment (Herlau [Her25], Subsection 4.3.2). We can think about it as a robot (in our case, a simulated robot) which gets information from the environment and decides which actions to take. The agent can (and often do) maintain an internal state for planning or learning. This internal state may include a model of the environment.- Training
Finally, the agent and environment must interact in the world loop (Herlau [Her25], Subsection 4.3.4). In this course this is accomplished using the
train()function. What it does it to feed observed states in the agent (i.e., call a method of the agent) which allows the agent to compute an action. This action is then fed back into the environment. This is sometimes called the world loop.
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}

An agent (represented by the yellow pacman) in an environment. Plot generated by the software in this course.#
Inventory environment#
The environment represents the problem we wish to solve. In reinforcement learning it could be a game, and in control theory it could be a simulation of e.g. a car driving around a track.
Nearly all environments will need to maintain an internal state \(x_k\). In a computer game, this represents the position of the player, enemies, etc., or in a control environment it represents positions and velocities of the object(s) that we are trying to control. To do this effectively, we represent environments using classes. For instance, the inventory environment defined as so:
Note
To be annoying, gymnasium environments typically denote the state by s (rather than \(x_k\)), and actions by a (rather than \(u_k\)). This notation is taken from reinforcement learning.
# inventory_environment.py
class InventoryEnvironment(Env):
def __init__(self, N=2):
self.N = N # planning horizon
self.action_space = Discrete(3) # Possible actions {0, 1, 2}
self.observation_space = Discrete(3) # Possible observations {0, 1, 2}
def reset(self):
self.s = 0 # reset initial state x0=0
self.k = 0 # reset time step k=0
return self.s, {} # Return the state we reset to (and an empty dict)
def step(self, a):
w = np.random.choice(3, p=(.1, .7, .2)) # Generate random disturbance
s_next = max(0, min(2, self.s-w+a)) # next state; x_{k+1} = f_k(x_k, u_k, w_k)
reward = -(a + (self.s + a - w)**2) # reward = -cost = -g_k(x_k, u_k, w_k)
terminated = self.k == self.N-1 # Have we terminated? (i.e. is k==N-1)
self.s = s_next # update environment state
self.k += 1 # update current time step
return s_next, reward, terminated, False, {} # return transition information
The following example shows how we can use the environment:
Note
You can ignore the info-dictionary for now.
It is useful in some reinforcement learning methods where the info-dictionary can be used to store extra information such as the (true) goal location for performance monitoring, but it is perhaps a bit annoying when you are just starting out.
Mathematically, recall the states and actions are denoted by:
When you call the gymnasium.Env.reset()-function, it returns the starting state \(x_0\) as the variable x0, as well as a dictionary info with optional extra information.
Tip
Since actions and observations can be both discrete and continuous, different environments will use different action and observation spaces depending on the situation.
In the example above they are instances of the Discrete observation space, representing integers \(\{0,1,2,\cdots,n-1\}\). You can
get \(n\) using env.observation_space.n and env.action_space.n.
The environment also defines two variables, the observation_space and the action_space. Lets take a look at both:
>>> import gymnasium as gym
>>> from irlc.ex01.inventory_environment import InventoryEnvironment
>>> env = InventoryEnvironment()
>>> print(env.observation_space)
Discrete(3)
>>> print(env.action_space)
Discrete(3)
>>> a = env.action_space.sample() # Get a random action
>>> print("Action is", a)
Action is 0
>>> print("Is this a valid action?", a in env.action_space, "is 9 a valid action?", 9 in env.action_space)
Is this a valid action? True is 9 a valid action? False
The observation and action spaces can be used to initialize the algorithm we want to use to solve the problem.
Conveniently, the spaces contains a gymnasium.spaces.Space.sample()-method which be used to generate a random action as follows: env.action_space.sample().
The step-function#
To actually take (execute) an action, you just need to pass it into the step()-function of the environment:
>>> from irlc.ex01.inventory_environment import InventoryEnvironment
>>> env = InventoryEnvironment()
>>> s0, _ = env.reset()
>>> next_state, reward, terminated, truncated, info = env.step(2) # Take action 2.
>>> print(f"Went from state {s0} to {next_state} when taking action 3 and got {reward=}")
Went from state 0 to 1 when taking action 3 and got reward=-3
In this example, we first reset the environment to get the starting state \(s_0\) as x0,
then tell the environment we want to take action \(a_0=2\), after which the step function returns 5 arguments:
Note
We use reward (and not cost) to be consistent with the gymnasium environment specification. You can get the cost by multiplying with minus one, i.e. cost = -reward.
next_state: The next state \(s_1\) (the one the state is in at the end of the program),reward: the first reward \(r_1\) (recall that the reward is 1-indexed)terminated: Aboolindicating if the environment terminated or not.truncated: Aboolindicating if the environment was forced to terminate prematurely. You can assume it isFalseinfo: A dictionary with possible extra information. Similar to the dictionary returned byreset.
You can assume the truncated-variable is False, and in most cases here in the beginning the info-dictionary will be empty.
Agents#
Tip
You can ignore the agents train()-function for now; we will return to it when we get to the reinforcement learning section of the course.
The Agent will be presented as a class with a policy method, which we denote by pi(), and a training-method denoted by train().
The following code defines an Agent which simply generates random actions (i.e. random numbers from the set \(\{0, 1, 2\}\)).
# inventory_environment.py
class RandomAgent(Agent):
def pi(self, s, k, info=None):
""" Return action to take in state s at time step k """
return np.random.choice(3) # Return a random action
Notice that the agent inherits from the class Agent – In this specific example this is cosmetic, but all agents you write should do this since it:
Ensures the function signature (order and number of parameters) to the
pi()andtrain()-function are the sameIt gives the agent access to a few helper functions. Most notably, the agent will by default implement a random policy – since many reinforcement learning methods requires us to take random actions some of the time (exploration), this will actually be quite helpful
Training#
The training function lets the agent and environment interact with each other, i.e., generate episodes. This is how we eventually train and test all of our methods (i.e., agents).
The training function is quite simple, and it is very useful to experiment with your own version first to really understand how the agent and environment interacts.
The main part of the code is the generation of a single rollout, which implements the world loop as described in (Herlau [Her25], Subsection 4.3.4), and which can be sketched as:
# inventory_environment.py
def simplified_train(env: Env, agent: Agent) -> float:
s, _ = env.reset()
J = 0 # Accumulated reward for this rollout
for k in range(1000):
a = agent.pi(s, k)
sp, r, terminated, truncated, metadata = env.step(a)
agent.train(s, a, sp, r, terminated)
s = sp
J += r
if terminated or truncated:
break
return J
Note
In the \(f_k, g_k\)-notation this is:
The last line will print out the total reward from one episode computed as:
where \(r_k\) is the reward-variable in each step.
Note
To summarize, the training-function will simulate the interaction between the agent and the environment for one episode as follows:
Reset the environment to get the first state
x0Uses the agents policy to compute the first action, i.e.
a0 = agent.pi(x0, 0)(the0refers to \(k=0\))Let the environment compute the next state using
env.step(a0)Repeat until the environment terminates.
The recommended train-function#
Although the train-function is very simple,
Eventually, you should use the train()-method I have written for reproducibility/simplicity, and because it provides more features such as experiment management.
A basic usage of the train()-function to train the agent for a single episode is as follows:
>>> from irlc.ex01.inventory_environment import InventoryEnvironment, RandomAgent
>>> from irlc import train # Import the train-function
>>> env = InventoryEnvironment() # set up an environment
>>> agent = RandomAgent(env) # Set up the RandomAgent (which takes random actions)
>>> stats, _ = train(env,agent,num_episodes=1,verbose=False) # Train for one complete episode (rollout)
>>> print("Accumulated reward of first episode:", stats[0]['Accumulated Reward'])
Accumulated reward of first episode: -2
The training function returns a stats-variable which is actually a dictionary. This is because we may want to know more about what happened during an episode than just the
accumulated reward. Here is what the variable will contain in general:
>>> from irlc.ex01.inventory_environment import InventoryEnvironment
>>> from irlc import Agent, train # Import the Agent and train-function
>>> env = InventoryEnvironment() # set up an environment
>>> agent = Agent(env) # Set up the default agent (which takes random actions)
>>> stats, _ = train(env,agent,num_episodes=1,verbose=False) # Train for one complete episode (rollout)
>>> for k in stats[0].keys():
... print(k, stats[0][k])
...
Episode 0
Accumulated Reward -4
Length 2
Steps 2
Multiple episodes#
The previous code only computed the average reward of a single episode of length \(N\) (num_episodes=1).
To estimate the average cost of a given policy we must do this \(T\) times and compute the average:
This is easily accomplished using the training function:
>>> import numpy as np
>>> from irlc import train, Agent
>>> from irlc.ex01.inventory_environment import InventoryEnvironment
>>> env = InventoryEnvironment()
>>> stats, _ = train(env, Agent(env), num_episodes=1000,verbose=False) # Perform 1000 rollouts using Agent class
>>> avg_reward = np.mean([stat['Accumulated Reward'] for stat in stats])
>>> print("[Agent class] Average cost of random policy J_pi_random(0)=", -avg_reward)
[Agent class] Average cost of random policy J_pi_random(0)= 4.17
This code computes:
What this tells us is how good our policy is on average, in this case the average cost is \(\approx 4\). When we design policies, the lower the expected cost is, the better the policy is.
The advantage of using the environment, agent and train-functionality is that we get a high degree of reuseability.
Note
It is not important how \(Q\)-learning works at this point. The example illustrates the environments and agents allows you to structure experiments in the same way throughout the course.
For instance, we can train a \(Q\)-learning agent, it will learn a better policy and therefore obtain a lower cost of \(2.75\):
>>> import numpy as np
>>> from irlc import train
>>> from irlc.ex10.q_agent import QAgent # You will implement q-learning in week 10.
>>> from irlc.ex01.inventory_environment import InventoryEnvironment
>>> env = InventoryEnvironment()
>>> stats, _ = train(env, QAgent(env), num_episodes=1000,verbose=False) # Perform 1000 rollouts using Agent class
>>> avg_reward = np.mean([stat['Accumulated Reward'] for stat in stats])
>>> print("[Agent class] Average cost of random policy J_pi_random(0)=", -avg_reward)
[Agent class] Average cost of random policy J_pi_random(0)= 2.821
Next week, we will compute the truly optimal cost.
Getting states and actions#
The second output argument of the training function gives you access to the states and actions computed in each episode. This code illustrates how you can print out the states and actions for 3 episodes:
>>> from irlc.ex01.inventory_environment import InventoryEnvironment
>>> from irlc import Agent, train # Import the Agent and train-function
>>> env = InventoryEnvironment() # set up an environment
>>> agent = Agent(env) # Set up the default agent (which takes random actions)
>>> _, trajectories = train(env,agent,num_episodes=3,verbose=False) # Train for three complete episodes
>>> for k, trajectory in enumerate(trajectories):
... print("episode", k, "states", trajectory.state)
... print("episode", k, "actions", trajectory.action)
...
episode 0 states [0, 0, 0]
episode 0 actions [np.int64(0), np.int64(0)]
episode 1 states [0, 0, 0]
episode 1 actions [np.int64(1), np.int64(2)]
episode 2 states [0, 0, 0]
episode 2 actions [np.int64(2), np.int64(0)]
Pacman#
The inventory-environment is a little bit boring, so we will lastly also look at the Pacman-example. Our goal is to build an agent that can play Pacman, but to get to that point we first need to familiarize ourselves with the Pacman game environment.
The Pacman levels are represented as a python str, which allows us to create varied Pacman environments. For instance, this is how we can craete
a Pacman game level based on a small maze with 4 food pellets:
>>> maze = """
... %%%%%%%
... % .%
... %.P%% %
... %. .%
... %%%%%%%
... """
>>> from irlc.pacman.pacman_environment import PacmanEnvironment
>>> env = PacmanEnvironment(maze)
>>> x0, _ = env.reset() # Works just like any other environment.
This requires a bit too much imagination, so you can plot the environment by passing render_mode='human' to the
environment (this is standard for gymnasium) and then use the plotenv()-function to plot it:
(Source code, png, hires.png, pdf)
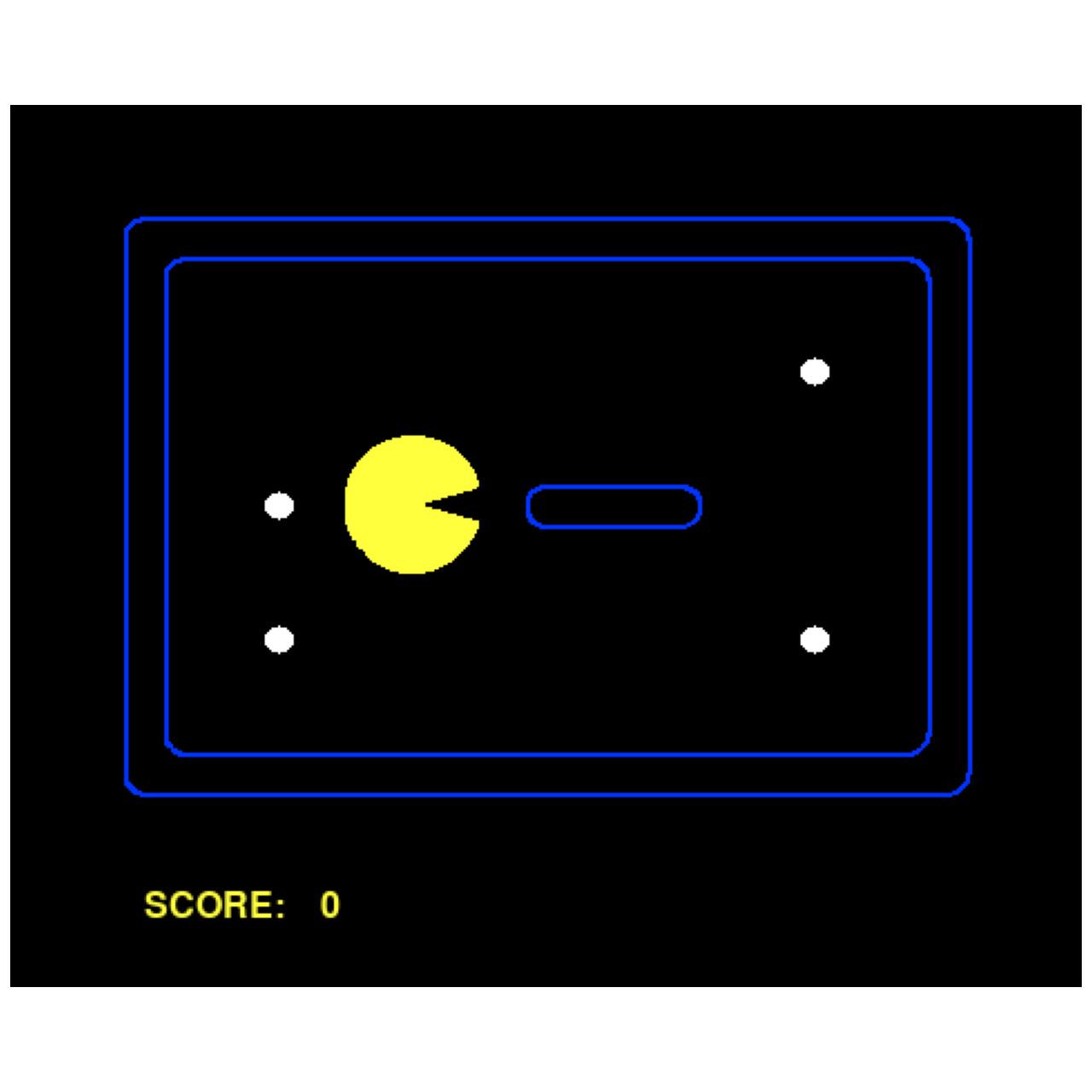{kind=link}
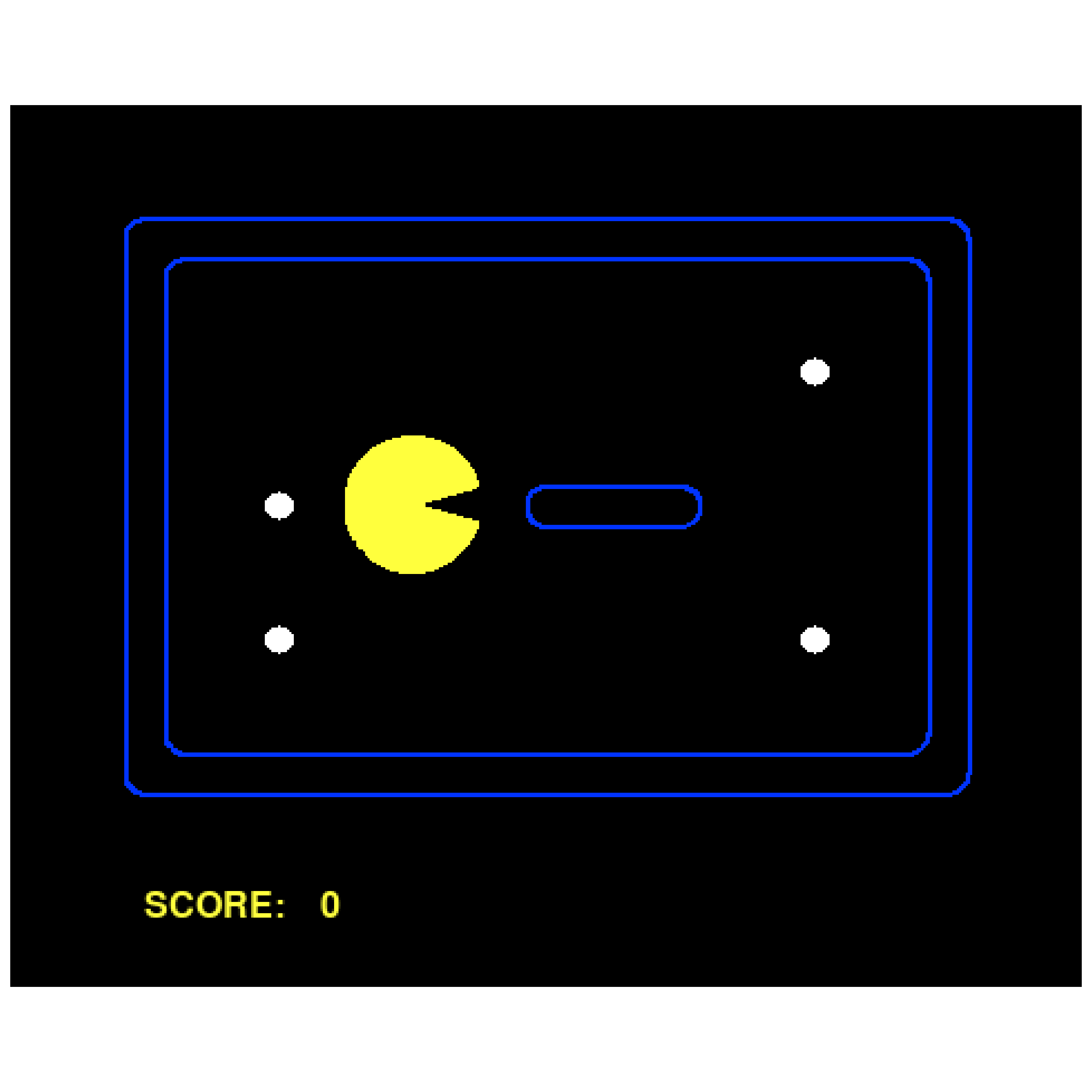{kind=link}
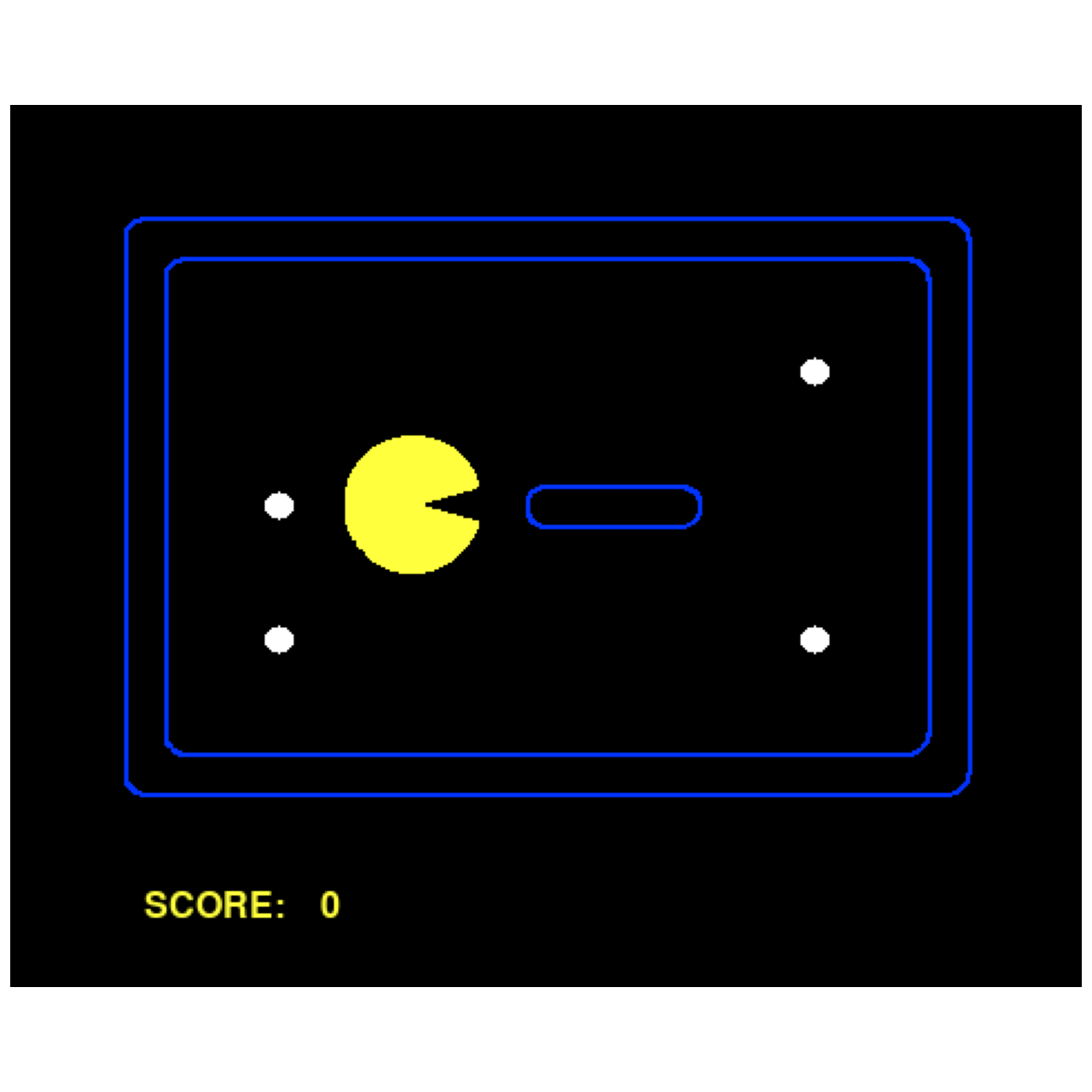
A basic example of plotting Pacman.#
If you want to try to play Pacman with a keyboard, you can copy-paste the following snippet into a text editor and it will work.
from irlc.pacman.pacman_environment import PacmanEnvironment, datadiscs
from irlc import interactive, Agent, train
env = PacmanEnvironment(layout_str=datadiscs, render_mode='human')
env, agent = Interactive(env, Agent(env)) # This makes the environment interactive. Ignore that it needs an Agent for now.
train(env, agent, num_episodes=2)
env.close()
The Pacman environment makes use of the freedom we have in specifying the actions and the states. For instance, the states are actually objects, so we can ask a state to tell us what actions are available:
>>> from irlc.pacman.pacman_environment import PacmanEnvironment, datadiscs
>>> env = PacmanEnvironment(layout_str=datadiscs)
>>> x0, _ = env.reset()
>>> print("Available actions in the starting state are", x0.A())
Available actions in the starting state are ['North', 'South', 'West', 'Stop']
>>> env.close()
It is important your agent only uses actions that are available in a given state, otherwise you will get an error like this:
Traceback (most recent call last):
File "<input>", line 1, in <module>
File "/builds/02465material/02465public/02465students_complete/irlc/pacman/pacman_environment.py", line 124, in step
raise Exception(f"Agent tried {action=} available actions {self.state.A()}")
Exception: Agent tried action='Right' available actions ['North', 'South', 'West', 'Stop']
Tip
In this case Pacman could eat both pellets by going down. To get more interesting behavior, use the variable k or the state x. The argument verbose=False to the irlc.agent.train()-function hides the progress bar.
Let’s put all of this together. The following example defines a level with two food pellets and a simple agent that eats both of them:
>>> maze = """
... %%%%%%%
... % P %
... % .%% %
... % . %
... %%%%%%%"""
>>> from irlc.pacman.pacman_environment import PacmanEnvironment
>>> from irlc import Agent, train
>>> env = PacmanEnvironment(maze)
>>> class HungryHippo(Agent): # All agents should inherit from the Agent class.
... def pi(self, x, k, info): # Implement the policy
... return "South" # The agent always takes the 'South'-action.
...
>>> stats, _ = train(env, HungryHippo(env), num_episodes=1, verbose=False)
>>> print("Your score was", stats[0]['Accumulated Reward'])
Your score was 518.0
>>> env.close()
Classes and functions#
- class irlc.ex01.agent.Agent(env)[source]#
The main agent class. See (Her25, Subsection 4.4.3) for additional details.
To use the agent class, you should first create an environment. In this case we will just create an instance of the
InventoryEnvironment(see (Her25, Subsection 4.2.3))- Example:
>>> from irlc import Agent # You can import directly from top-level package >>> import numpy as np >>> np.random.seed(42) # Fix the seed for reproduciability >>> from irlc.ex01.inventory_environment import InventoryEnvironment >>> env = InventoryEnvironment() # Create an instance of the environment >>> agent = Agent(env) # Create an instance of the agent. >>> s0, info0 = env.reset() # Always call reset to start the environment >>> a0 = agent.pi(s0, k=0, info=info0) # Tell the agent to compute action $a_{k=0}$ >>> print(f"In state {s0=}, the agent took the action {a0=}") In state s0=0, the agent took the action a0=np.int64(0)
- __init__(env)[source]#
Instantiate the Agent class.
The agent is given the openai gym environment it must interact with. This allows the agent to know what the action and observation space is.
- Parameters:
env (
Env) – The openai gymEnvinstance the agent should interact with.
- pi(s, k, info=None)[source]#
Evaluate the Agent’s policy (i.e., compute the action the agent want to take) at time step
kin states.This correspond to the environment being in a state evaluating \(x_k\), and the function should compute the next action the agent wish to take:
\[u_k = \mu_k(x_k)\]This means that
s= \(x_k\) andk= \(k =\{0, 1, ...\}\). The function should return an action that lies in the action-space of the environment.- The info dictionary:
The
info-dictionary contains possible extra information returned from the environment, for instance when calling thes, info = env.reset()function. The main use in this course is in control, where the dictionary contains a valueinfo['time_seconds'](which corresponds to the simulation time \(t\) in seconds).We will also use the info dictionary to let the agent know certain actions are not available. This is done by setting the
info['mask']-key. Note that this is only relevant for reinforcement learning, and you should see the documentation/exercises for reinforcement learning for additional details.
The default behavior of the agent is to return a random action. An example:
>>> from irlc.pacman.pacman_environment import PacmanEnvironment >>> from irlc import Agent >>> env = PacmanEnvironment() >>> s, info = env.reset() >>> agent = Agent(env) >>> agent.pi(s, k=0, info=info) # get a random action 'South' >>> agent.pi(s, k=0) # If info is not specified, all actions are assumed permissible. 'North'
- Parameters:
s – Current state the environment is in.
timestep – Current time
- Returns:
The action the agent want to take in the given state at the given time. By default the agent returns a random action
- train(s, a, r, sp, done=False, info_s=None, info_sp=None)[source]#
Implement this function if the agent has to learn (be trained).
Note that you only have to implement this function from week 7 onwards – before that, we are not interested in control methods that learn.
The agent takes a number of input arguments. You should imagine that
sis the current state \(x_k`\)ais the action the agent took in states, i.e.a\(= u_k = \mu_k(x_k)\)ris the reward the the agent got from that actionsp(s-plus) is the state the environment then transitioned to, i.e.sp\(= x_{k+1}\)‘
donetells the agent if the environment has stoppedinfo_sis the information-dictionary returned by the environment as it transitioned tosinfo_spis the information-dictionary returned by the environment as it transitioned tosp.
The following example will hopefully clarify it by showing how you would manually call the train-function once:
- Example:
>>> from irlc.ex01.inventory_environment import InventoryEnvironment # import environment >>> from irlc import Agent >>> env = InventoryEnvironment() # Create an instance of the environment >>> agent = Agent(env) # Create an instance of the agent. >>> s, info_s = env.reset() # s is the current state >>> a = agent.pi(s, k=0, info=info_s) # The agent takes an action >>> sp, r, done, _, info_sp = env.step(a) # Environment updates >>> agent.train(s, a, r, sp, done, info_s, info_sp) # How the training function is called
In control and dynamical programming, please recall that the reward is equal to minus the cost.
- Parameters:
s – Current state \(x_k\)
a – Action taken \(u_k\)
r – Reward obtained by taking action \(a_k\) in state \(x_k\)
sp – The state that the environment transitioned to \({\\bf x}_{k+1}\)
info_s – The information dictionary corresponding to
sreturned byenv.reset(when \(k=0\)) and otherwiseenv.step.info_sp – The information-dictionary corresponding to
spreturned byenv.stepdone – Whether environment terminated when transitioning to
sp
- Returns:
None
- irlc.ex01.agent.train(env, agent=None, experiment_name=None, num_episodes=1, verbose=True, reset=True, max_steps=10000000000.0, max_runs=None, return_trajectory=True, resume_stats=None, log_interval=1, delete_old_experiments=False, seed=None)[source]#
This function implements the main training loop as described in (Her25, Subsection 4.4.4).
The loop will simulate the interaction between agent agent and the environment env. The function has a lot of special functionality, so it is useful to consider the common cases. An example:
>>> stats, _ = train(env, agent, num_episodes=2)
Simulate interaction for two episodes (i.e. environment terminates two times and is reset). stats will be a list of length two containing information from each run
>>> stats, trajectories = train(env, agent, num_episodes=2, return_Trajectory=True)
trajectories will be a list of length two containing information from the two trajectories.
>>> stats, _ = train(env, agent, experiment_name='experiments/my_run', num_episodes=2)
Save stats, and trajectories, to a file which can easily be loaded/plotted (see course software for examples of this). The file will be time-stamped so using several calls you can repeat the same experiment (run) many times.
>>> stats, _ = train(env, agent, experiment_name='experiments/my_run', num_episodes=2, max_runs=10)
As above, but do not perform more than 10 runs. Useful for repeated experiments.
- Parameters:
env – An openai-Gym
Envinstance (the environment)agent – An
Agentinstanceexperiment_name – The outcome of this experiment will be saved in a folder with this name. This will allow you to run multiple (repeated) experiment and visualize the results in a single plot, which is very important in reinforcement learning.
num_episodes – Number of episodes to simulate
verbose – Display progress bar
reset – Call
env.reset()before simulation start. Default isTrue. This is only useful in very rare cases.max_steps – Terminate if this many steps have elapsed (for non-terminating environments)
max_runs – Maximum number of repeated experiments (requires
experiment_name)return_trajectory – Return trajectories list (Off by default since it might consume lots of memory)
resume_stats – Resume stat collection from last run (this requires the
experiment_namevariable to be set)log_interval – Log stats less frequently than each episode. Useful if you want to run really long experiments.
delete_old_experiments – If true, old saved experiments will be deleted. This is useful during debugging.
seed – An integer. The random number generator of the environment will be reset to this seed allowing for reproducible results.
- Returns:
A list where each element corresponds to each (started) episode. The elements are dictionaries, and contain the statistics for that episode.
- irlc.utils.player_wrapper.interactive(env, agent, autoplay=False)[source]#
This function is used for visualizations. It can
Allow you to input keyboard commands to an environment
Allow you to save results
Visualize reinforcement-learning agents in the gridworld environment.
by adding a single extra line
env, agent = interactive(env,agent). The following shows an example:>>> from irlc.gridworld.gridworld_environments import BookGridEnvironment >>> from irlc import train, Agent, interactive >>> env = BookGridEnvironment(render_mode="human", zoom=0.8) # Pass render_mode='human' for visualization. >>> env, agent = interactive(env, Agent(env)) # Make the environment interactive. Note that it needs an agent. >>> train(env, agent, num_episodes=2) # You can train and use the agent and environment as usual. >>> env.close()
It also enables you to visualize the environment at a matplotlib figure or save it as a pdf file using
env.plot()andenv.savepdf('my_file.pdf).All demos and figures in the notes are made using this function.
- Parameters:
- Return type:
- Returns:
An environment and agent which have been slightly updated to make them interact with each other. You can use them as usual with the
train-function.
- irlc.plotenv(env)[source]#
Given a Gymnasium environment instance, this function will plot the environment as a matplotlib image. Remember to call
plt.show()to actually see the image.For this function to work, you must create the environment with
render_mode='human'.Note
This function may not work for all gymnasium environments, however, it will work for most environments we use in this course.
- Parameters:
env (
Env) – The environment to plot.
Solutions to selected exercises#
Solution to problem 1
Part a: For action \(u=0\) Bob ends up with \(1.1x_0\) kroner. For action \(u=1\) bob ends up with
If we plug in \(x_0 = 20\) we get 22 when \(u=0\) and \(24\) when \(u=1\) so \(u=1\) is right.
Part b: The policy depends on \(x_0\). It outputs \(u=0\) when
Simplifying this we get: \(\mu_0(x_0) = 0\) when \(x_0 < \frac{180}{7}\) and otherwise \(\mu_0(x_0) = 1\).
Problem 3 & 4: Inventory control
Problem 5
Problem 6